




Nom : YAO Hermann Archambaud
Sexe : Masculin
Formation :Il est Ingénieur d’État des Systèmes Réseaux et Télécommunications, ayant fait les Classes Préparatoires MPSI et MP. Il possède de nombreuses certifications sur des solutions Oracle, Wallix, Talend notamment.Expérience professionnelle : Après des débuts dans le domaine du Support et de l’infogérance, il s’est tourné vers les métiers de la data. Il est depuis 2019, Ingénieur Intelligence Artificielle et BIG DATA au sein du cabinet EBENYX TECHNOLOGIES.Technologies utilisées : En tant qu’ingénieur IA et BIG DATA, il travaille beaucoup avec le language Python. Il utilise des technologies open sources et propriétaires telles que PostgreSQL, Apache Superset, Apache Spark, Oracle Analytics Cloud, Power BI, SAP, Tableau pour ce citer que celles-ci.
Qu’est-ce qu’est l’Analyse Exploratoire de Données ?
L’Analyse Exploratoire de Données (ou EDA ou Exploratory Data Analysis en anglais) fait référence au processus critique consistant à effectuer des enquêtes initiales sur les données afin de découvrir des modèles, de repérer des anomalies, et de vérifier des hypothèses à l’aide de statistiques récapitulatives et de représentations graphiques.C’est une bonne pratique pour comprendre les données d’abord et d’essayer d’en tirer autant d’informations ensuite. L’EDA consiste à donner un sens aux données en main, avant d’en extraire des connaissances.
Développées à l’origine par le mathématicien américain John Tukey dans les années 1970, les techniques EDA continuent d’être une méthode largement utilisée dans le processus de découverte de données aujourd’hui.
Pourquoi l’Analyse Exploratoire de Données est-elle importante en science des données ?
Le but de l’EDA est d’aider à examiner les données avant de faire des hypothèses. Cela peut aider à identifier les erreurs évidentes, ainsi qu’à mieux comprendre les modèles au sein des données, à détecter les valeurs aberrantes ou les événements anormaux, à trouver des relations intéressantes entre les variables. Les data scientistes peuvent utiliser une analyse exploratoire pour s’assurer que les résultats qu’ils produisent sont valides et applicables à tous les résultats et objectifs commerciaux souhaités. EDA aide également les parties prenantes en confirmant qu’elles posent les bonnes questions. L’EDA peut aider à répondre aux questions sur les écarts types, les variables catégorielles et les intervalles de confiance. Une fois l’EDA terminée et les informations tirées, ses fonctionnalités peuvent ensuite être utilisées pour une analyse ou une modélisation plus sophistiquée des données, y compris l’apprentissage automatique.
Quelques avantages de l’analyse exploratoire des données : – Améliorer la compréhension des variables en extrayant des moyennes, des valeurs moyennes, minimales et maximales notamment. – Découvrir des erreurs, les valeurs aberrantes et les valeurs manquantes. – Identifier des modèles dans les données en les visualisant dans des graphiques tels que des histogrammes, des nuages de points ou des camemberts.
Ainsi, l’objectif principal est de mieux comprendre les données et d’utiliser efficacement les outils pour obtenir des informations précieuses ou tirer des conclusions.
Outils d’analyse exploratoire de données
Les langages Python et R sont les deux outils de science des données les plus couramment utilisés pour créer un EDA.
Python : l’analyse exploratoire de données peut être faite en utilisant python pour identifier la valeur manquante dans un ensemble de données. Les autres fonctions qui peuvent être exécutées sont la description des données, la gestion des valeurs aberrantes, l’obtention d’informations à travers les graphiques. En raison de sa structure de données intégrée de haut niveau, ainsi que du typage et de la liaison dynamiques, Python est un outil attrayant pour l’EDA.L’analyse d’un jeu de données est une tâche trépidante qui prend beaucoup de temps. Python fournit certains modules et bibliothèques open source qui peuvent automatiser l’ensemble du processus d’EDA et contribuer à un gain de temps. R : Le langage R est largement utilisé par les data scientists et les statisticiens pour développer des observations statistiques et des analyses de données. R est un langage de programmation open source qui fournit un environnement logiciel gratuit pour le calcul statistique et les graphiques pris en charge par la R Foundation for Statistical Computing. Pour le cas pratique de la section suivante, nous utiliserons le langage Python.
Cas pratique : Analyse des données issues des jeux olympiques de 1896 à 2016
Objectif : Faire un EDA en utilisant Python pour analyser et visualiser les données des jeux olympiques passés et répondre à des questions spécifiques Les Jeux Olympiques (JO) sont un événement sportif populaire. Ils ont été initiés en 1896 à Athènes, en Grèce. Les derniers en date, du fait de la COVID-19 se sont déroulés en 2021 au Japon.

Logo des Jeux Olympiques
Les 5 anneaux dans le logo représentent les 05 continents : Europe, Afrique, Asie, les Amériques et Océanie.
Présentation du jeu de données
Le dataset (jeu de données) utilisé dans ce cas pratique, est téléchargeable sur la plateforme Kaggle via ce lien– https://www.kaggle.com/heesoo37/120-years-of-olympic-history-athletes-and-results . Kaggle permet de rechercher et de publier des ensembles de données, d’explorer et de créer des modèles dans un environnement de science des données basé sur le Web, de travailler avec d’autres data scientists et ingénieurs en apprentissage automatique et de participer à des concours pour résoudre les défis de la science des données.
Utilisation de jupyter notebook
Jupyter Notebook est une application Web open source qui permet de créer et de partager des documents contenant du code en direct, des équations, des visualisations et du texte narratif. Les utilisations incluent : le nettoyage et la transformation des données, la simulation numérique, la modélisation statistique, la visualisation des données, l’apprentissage automatique et bien plus encore. Nous l’utiliserons ici dans le cadre de notre EDA sur les données des jeux olympiques.
Codes python
Import des librairies standards

Chargement du jeu de données

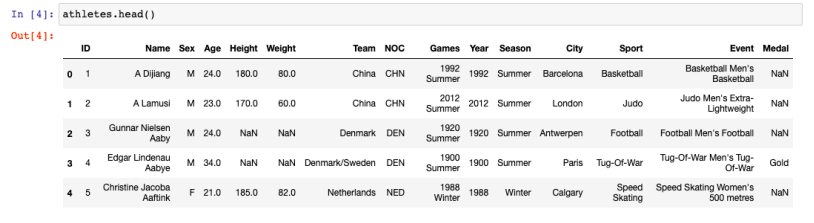
Affichage des données avec la méthode head()
=> Cette méthode affiche les 5 premières lignes des dataframes athletes et regions

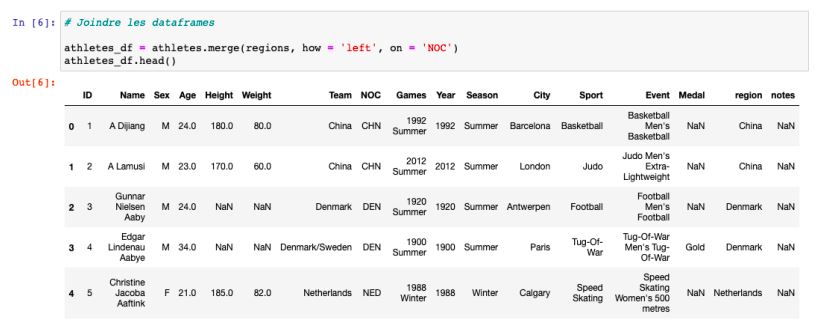
Jointure des deux dataframes athletes et regions avec la méthode merge()
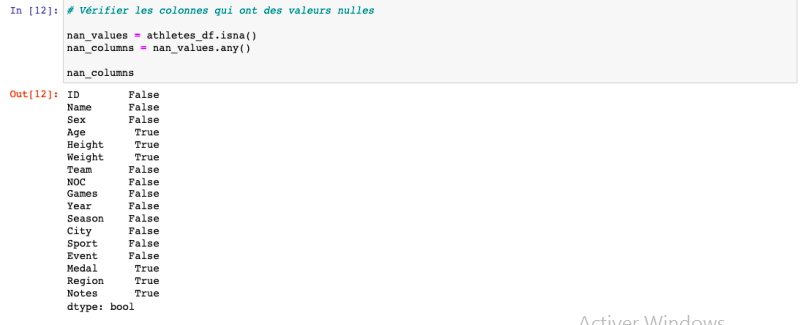
Vérification des colonnes ayant des valeurs nulles
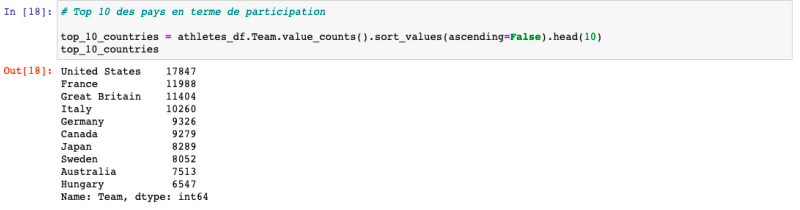
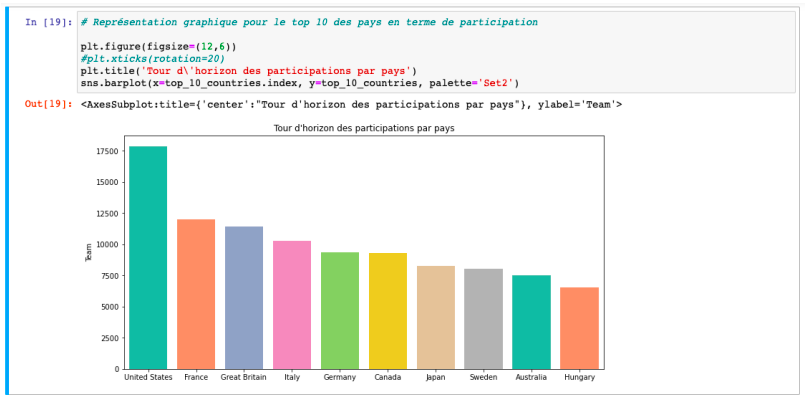
Affichage du Top10 des pays en terme de participation
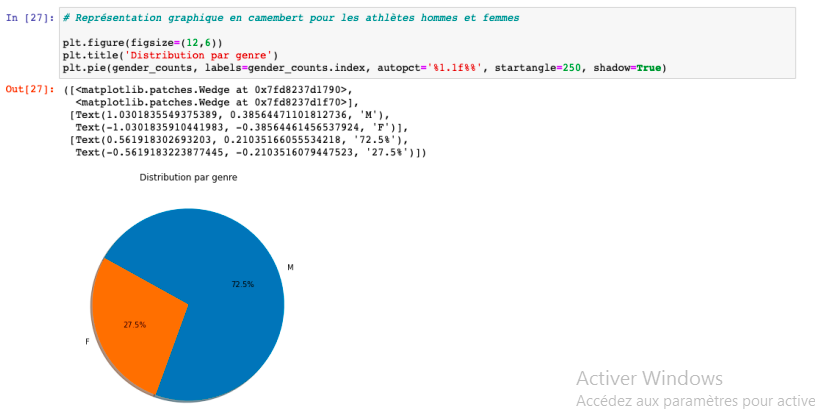
Distribution par genre en pourcentage de participation aux jeux olympiques depuis la création jusqu’en 2016
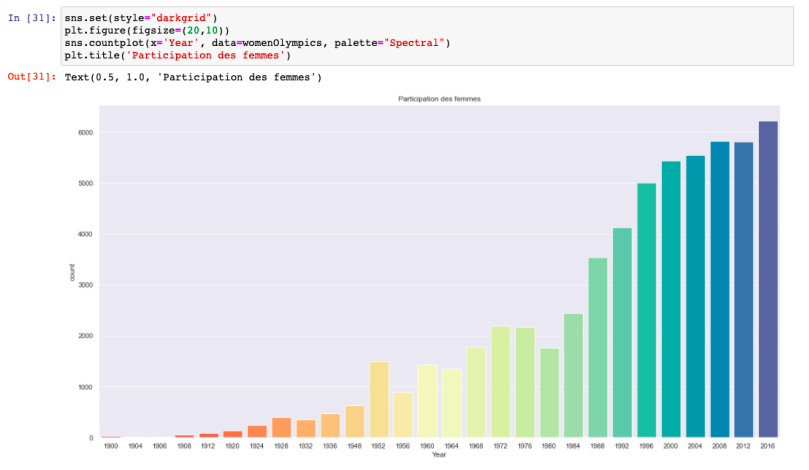
Participation des femmes aux jeux olympiques sur la période 1896-2016
L’EDA est une des étapes à réaliser en amont, avant de plonger dans l’apprentissage automatique ou la modélisation statistique, car elle fournit le contexte nécessaire pour développer un modèle approprié au problème posé et pour interpréter correctement ses résultats. L’EDA est utile au data scientist pour s’assurer que les résultats qu’il produit sont valides, correctement interprétés et applicables aux contextes commerciaux souhaités.
https://www.educative.io/edpresso/what-is-exploratory-data-analysis
https://www.ibm.com/cloud/learn/exploratory-data-analysis
https://jupyter.org/
https://analyticsindiamag.com/exploratory-data-analysis-functions-types-tools/
https://chartio.com/learn/data-analytics/what-is-exploratory-data-analysis/