




Auteur : EBENYX TECHNOLOGIES
La vision par ordinateur et les CNN
Depuis quelques années, l’Intelligence Artificielle (IA) fait l’objet d’une médiatisation et d’une attention sans précédent. Ce fort regain d’intérêt pour l’IA est notamment lié à d’importantes avancées technologiques qui ont permis d’accroître de façon considérable les performances des ordinateurs dans de nombreux domaines comme la reconnaissance automatique de la parole et la vision par ordinateur. Ces avancées ont ouvert de vastes perspectives d’introduction à l’IA sous différentes formes. Un point particulièrement notable est que de plus en plus de secteurs sont concernés par ce domaine tel que la finance, les banques, les assurances et bien d’autres. L’IA occupe une place de plus en plus importante dans les organisations et les systèmes de productions, en effet ces champs d’application ne cessent de se multiplier. De l’automatisation de tâches à l’analyse de grandes bases de données en passant par la logistique, l’analyse prédictive, l’IA est présente. Son vaste domaine d’application est dû au fait qu’elle est le plus souvent vue, comme un ensemble de technologies pouvant produire de nombreux bénéfices, notamment en termes de performance et parfois en termes de facilitation du travail voire la réduction de la pénibilité en permettant l’automatisation des tâches fastidieuses ou répétitives. Dans cet article nous vous parlerons d’un domaine revolutionnel de l’intelligence artificielle : la vision par ordinateur.
Qu’est que la vision par ordinateur ?
La vision par ordinateur est un domaine scientifique interdisciplinaire qui traite de la façon dont les ordinateurs peuvent acquérir une compréhension de haut niveau à partir d’images ou de vidéos numériques. Du point de vue de l’ingénierie, il cherche à comprendre et à automatiser les tâches que le système visuel humain peut effectuer.Les tâches de vision par ordinateur comprennent des procédés pour acquérir , traiter, analyser et « comprendre » des images numériques, et extraire des données afin de produire des informations numériques ou symboliques, par ex. sous forme de décisions. Dans ce contexte, la compréhension signifie la transformation d’images visuelles (l’entrée de la rétine) en descriptions du monde qui ont un sens pour les processus de pensée et peuvent susciter une action appropriée. Cette compréhension de l’image peut être vue comme l’acquisition d’informations symboliques à partir de données d’image à l’aide de modèles construits à l’aide de la géométrie , de la physique des statistiques et de la théorie de l’apprentissage . La discipline scientifique de la vision par ordinateur s’intéresse à la théorie des systèmes artificiels qui extraient des informations à partir d’images. Les données d’image peuvent prendre de nombreuses formes, telles que des séquences vidéo, des vues de plusieurs caméras, des données multidimensionnelles à partir d’un scanner 3D ou d’un appareil de numérisation médical. La discipline technologique de la vision par ordinateur cherche à appliquer les modèles théoriques développés à la construction de systèmes de vision par ordinateur.
Les réseaux de neurones convolutifs : le réseau de neurone artificiels le plus adapté à la.
Avant d’aborder les neurones artificiels, examinons rapidement les neurones biologiques. Il s’agit d’une cellule à l’aspect inhabituel que l’on trouve principalement dans les cortex cérébraux (par exemple, le cerveau humain). Elle est constituée d’un corps cellulaire, qui comprend le noyau et la plupart des éléments complexes de la cellule, ainsi que de nombreux prolongements appelés dendrites et un très long prolongement appelé axone. L’axone peut être juste un peu plus long que le corps cellulaire, mais aussi jusqu’à des dizaines de milliers de fois plus long. Près de son extrémité, il se décompose en plusieurs ramifications appelées télodendrons, qui se terminent par des structures minuscules appelées synapses et reliées aux dendrites (ou directement au corps cellulaire) d’autres neurones. Par l’intermédiaire de ces synapses, les neurones biologiques reçoivent des autres neurones de courtes impulsions, appelées signaux. Lorsqu’un neurone reçoit en quelques millisecondes un nombre suffisant de signaux, il déclenche ses propres signaux. L’image si dessous represente un neurone artificiel.

Les réseau de neurones artificiels sont au cœur de l’apprentissage profond1. Ils sont polyvalents, puissants et extensibles, ce qui les rend parfaitement adaptés aux tâches d’apprentissage automatique extrêmement complexes, comme la classification de millions d’images (par exemple, Google Images), la reconnaissance vocale (par exemple, Apple Siri). Dans le domaine de la vision par ordinateur , les réseaux les plus appropriés sont les réseaux de neurones convolutifs (CNN).
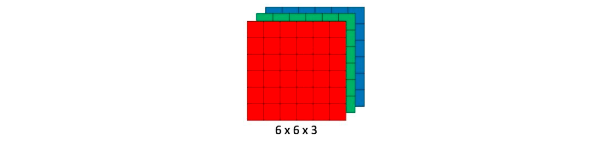
Dans les réseaux de neurones, le CNN est l’une des principales catégories permettant d’extraire les caractéristiques dans une image. Dans les réseaux de neurones, le CNN est l’une des principales catégories permettant d’extraire les caractéristiques dans une image. Pour ce faire, les CNN prennent en entrée une image, la traite et la classe dans certaines catégories. Les ordinateurs voient une image d’entrée comme un tableau de pixels et cela dépend de la résolution de l’image. En fonction de la résolution de l’image, ℎ × 𝑤 × 𝑑 apparaît (h = hauteur, w = largeur, d = dimension). Par exemple, une image de 6 x 6 x 3 est un tableau de matrice de Rouge Vert Bleu (RVB) (3 se réfère à des valeurs RVB) et une image de 4 x 4 x 1 est un tableau de matrice d’image en niveaux de gris.
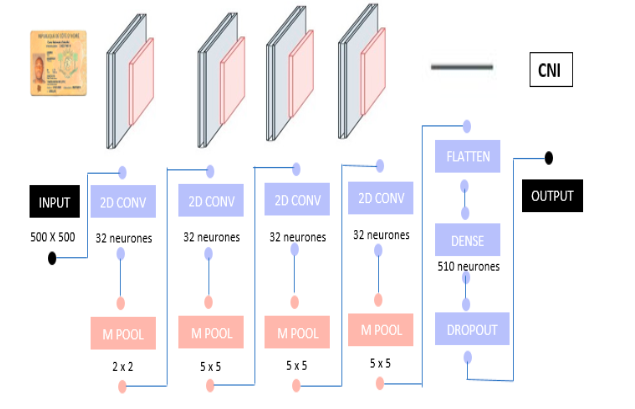
L’architecture des CNN est constituée d’une ou de plusieurs couches de convolutions, chaque couche de convolution étant suivi d’une couche de Pooling, ensuite vient le réseau de neurones entièrement connecté (FC-Full connected) et d’une fonction Softmax à la sortie qui permet de classer un document avec des valeurs probabilistes comprises entre 0 et 1.

Couches d’entrées La couche d’entrée d’un CNN est construite généralement avec plusieurs couches de convolution, associés à des couches de mise en commun. L’idée de la couche de convolution est de transformer l’image d’entrée afin d’extraire des caractéristiques pour distinguer correctement les documents. Cela se fait en convoluant l’image avec un noyau. Le noyau est spécialisé pour extraire certaines fonctionnalités. Il est possible d’appliquer plusieurs noyaux à une seule image pour capturer plusieurs fonctionnalités. Le travail de la couche de mise en commun est de réduire la taille de l’image. Il ne conservera que les fonctionnalités les plus importantes et supprimera l’autre zone de l’image. De plus, cela réduira également le coût de calcul. La plupart des stratégies de mise en commun populaires sont max mise en commun et la mise en commun moyenne. Le Pooling est très important, en réduisant l’image, le nombre de données traitées diminue et donc le temps de calcul sera lui aussi réduit. Cela n’est pas négligeable. Couches profondes et la couche de sortieUne fois que les étapes de convolutions sont opérées, les patterns obtenus en sortie sont injectés comme données d’entrée dans un réseau neuronal classique. Le but de celui-ci est de classifier les données en déduisant une probabilité sur les différents résultats possibles. Néanmoins pour injecter les patterns issus du réseau à convolution dans le réseau neuronal, on passe par une étape dite de « Flattening » (ou aplatissement). Cette opération consiste à mettre à plat toutes les données dans un seul vecteur. Toutes les « images » sont ainsi mises bout à bout dans un même vecteur. Ce vecteur sera injecté dans une couche de neurones entièrement connectée de plusieurs neurones. C’est à dire que chacune des valeurs de ce vecteur sera connectée aux neurones de la couche entièrement connectée permettant la classification de l’image. La sortie de cette couche sera l’entrée d’une couche Dropout, et enfin la dernière couche sera une couche dense dont le nombre de neurone dépend du nombre de classe en sortie avec softmax comme fonction d’activation. Exemple d’un réseau de neurone convolutifs
1 couche de convolution de 32 canaux de 5×5 kernal et même rembourrage
1 couche maxpool de taille de piscine 2×2 et foulée 2×2
1 couche de convolution de 32 canaux de 5×5 kernal et même rembourrage
1 couche maxpool de taille de piscine 2×2 et foulée 2×2
1 couche de convolution de 32 canaux de 5×5 kernal et même rembourrage
1 couche maxpool de taille de piscine 2×2 et foulée 2×2
1 couche de convolution de 32 canaux de 5×5 kernal et même rembourrage
1 couche maxpool de taille de piscine 2×2 et foulée 2×2
1 couche de dropout
1 couche dense de 510 unités 1 couche Softmax dense de 3 unités
BIBIOGRAPHIE
[1] Livre Consulté le 13/02/2020
https://www.lrde.epita.fr/~sigoure/cours_ReseauxNeurones.pdf
[2] Livre Consulté le 25/02/2020
http://www.iro.umontreal.ca/~aimeur/cours/ift6261/Ch1-Intro-IA-IFT6261-H-11.pdf [3] Livre Consulté le 01/03/2020
https://www.enib.fr/~deloor/materielPedagogique/IA/IAS20172018_Cours_1.pdf
WEBOGRAPHIE
[4] Consulté le 05/03/2020
https://journals.openedition.org/activites/4941
[5] Consulté le 12/04/2020
https://www.tensorflow.org/tutorials/images/classification
https://missinglink.ai/guides/tensorflow/tensorflow-image-classification/
[6] Consulté le 25/04/2020
https://medium.com/edureka/tensorflow-image-classification-19b63b7bfd95
https://blog.francium.tech/build-your-own-image-classifier-with-tensorflow-and-keras-dc147a15e38e
https://nanonets.com/blog/ocr-with-tesseract/
https://pythonprogramming.net/thresholding-image-analysis-python-opencv-tutorial/
[7] Consulté le 09/05/2020
https://cv-tricks.com/tensorflow-tutorial/training-convolutional-neural-network-for-image-classification/
https://www.datacorner.fr/analyser-les-elements-dune-carte-didentite/https://stackoverrun.com/fr/q/8196872
https://flask.palletsprojects.com/en/1.0.x/quickstart/#routing