




Auteur : EBENYX TECHNOLOGIES

Web Scraping pour des fins de l’Intelligence Artificielle
Toute entité morale ou physique qui travaille avec une grande masse de donnée est bien consciente que la première étape avant de collecter des informations publiques consiste à déterminer les données exactes dont elle a besoins. Et cette étape est complexe et plus importante que l’obtention des données finales elles-mêmes.
Dans cet article, DOUMBIA Abdoulaye, Stagiaire en Intelligence Artificielle chez EBENYX TECHNOLOGIE, présentera pourquoi et comment les entités peuvent utiliser le Web Scraping et l’Intelligence Artificielle pour améliorer leur image de marque et aussi de fidéliser leur clientèle.
Pourquoi le Web scraping !
Web scraping, c’est le fait d’extraire des informations parties du web, qui ne peut être copié collé sans dénaturer la structure même du document. On peut extraire des articles, des tableaux, des photos, des vidéos et ce qu’on a pu extraire alors on peut bien sûr l’étudier afin de retirer d’autres informations qui peut être intéressant pour l’entreprise.
Cette technique est utilisée dans plusieurs domaines : par exemple dans le domaine du marketing, pour extraire les numéros du téléphone à parti d’un email, dans le domaine des e-commerces, on peut extraire les commentaires des clients pour voir leur sentiment de cet article aussi le prix des produits en temps réel sur le marché ainsi que le nombre d’achat par article … Alors le Web Scraping possède de multiples intérêts et est utilisé dans divers secteurs :
- Dans la surveillance des prix :
- Surveillance des concurrents
- Suivi des tendances des produits
- Prise de décision en matière d’investissement
- Dans le secteur de l’immobilier :
- Comprendre l’orientation du marché
- Estimer des rendements locatifs
- Evaluer la valeur des biens
- Dans l’analyse de sentiments :
- Prise de décision en matière d’investissement
- Surveillance des produits
- Dans le suivi de l’actualité :
- En campagne politique
- En analyse des sentiments du public en ligne
Un exemple parlant de web scraping avec python
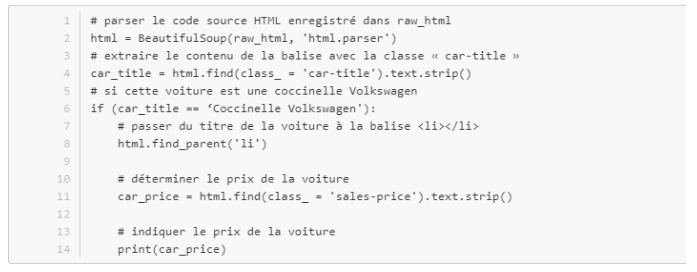
Imaginez un site Internet de vente de voiture d’occasion. Lorsque vous accédez à la page dans votre navigateur, une liste de voiture vous est affichée. Regardons par exemple le code source correspondant à une voiture :

Un web scraping peut parcourir la liste de véhicule d’occasion disponible en ligne. Conformément à l’intention de son créateur, le scraper recherche un modèle en particulier : dans notre exemple, il s’agit d’une coccinelle Volkswagen. Dans le code source, la marque et le modèle de la voiture sont précisés dans les classes CSS « car-make » et « car-model ». Ces intitulés de classes permettent de rechercher facilement les informations souhaitées. Voici un exemple avec BeautifulSoup :
Donc, maintenant que vous connaissez les bases du Web Scraping. Vous vous demandez probablement quel est le meilleur moyen de scraper le web ?
Web Scraping aide-t-il les entreprises ?
Vous pouvez obtenir des flux de produits, des images, des prix et d’autres détails connexes concernant le produit à partir de divers sites et créer votre entrepôt de données ou votre site de comparaison de prix.
Vous pouvez examiner le fonctionnement d’un produit particulier, le comportement de l’utilisateur et les commentaires selon vos besoins.
En cette ère de numérisation, les entreprises sont fortes sur les dépenses consacrées à la gestion de la réputation en ligne. Il est devenu une pratique courante pour les individus de lire des opinions et des articles en ligne à diverses fins. Il est donc crucial d’ajouter le spam d’impression.En grattant les résultats de recherche organiques, vous pouvez instantanément découvrir vos concurrents SEO pour un terme de recherche spécifique. Vous pouvez comprendre les balises de titre et les mots-clés que d’autres prévoient. Risque juridiques du web scraping
Risques juridiques du web scraping
Malgré son aspect pratique, le web scraping s’accompagne de risques juridiques. En principe, l’exploitant d’un site Internet met sa page à disposition pour une utilisation par des êtres humains. Une consultation automatisée à l’aide d’un web scraper peut donc constituer une violation des conditions d’utilisation. C’est notamment le cas lorsque la consultation est effectuée massivement sur plusieurs pages, que ce soit simultanément ou fréquemment. Aucun être humain ne pourrait interagir avec le site de cette façon.Par ailleurs, la consultation, l’enregistrement et l’analyse automatisés des données publiées sur un site Internet peuvent, le cas échéant, représenter une violation des droits d’auteur. Si les information scrapées sont des données permettant une identification personnelle, l’enregistrement et l’analyse sans autorisation de la personne concernée représentent une violation des dispositions applicables en matière de protection des données. Le fait de scraper des profils Facebook pour collecter des données à caractère personnel est par exemple interdit.
Pour répondre aux besoins des entreprises
Après les différentes étapes
Étape 1 : Définissez vos besoins en matière de données
Étape 2 : Mener un examen juridique
Étape 3 : Évaluer la faisabilité technique Nous pouvions concevoir une solution et estimer les ressources à l’aide des outils de machine Learning et Deep Learning Veuillez prendre contact avec notre équipe au sein de EBENYX TECHNOLOGIES.